
Гайд: Мониторинг и алерты: как настроить HiveOS/AwesomeMiner

Немного контекста. Мониторинг — это не только цифры. Это процесс: измерять, фильтровать шум, давать сигналы людям, которые реально что-то сделают. Если вы оператор — вам нужен не миллион графиков, а несколько разумных правил и план действий. Дальше — по шагам.
1. Базовые принципы мониторинга фермы
- Сначала — здоровье машины. Потом — доход. Сначала — температура, питание, вентиляторы, сеть, затем хешрейт и пул.
- Срабатывание алерта = действие. Каждый алерт должен иметь владельца и сценарий, что сделать дальше.
- Меньше ложных срабатываний. Стоп-лоссы и «хистори» — используйте задержки и подтверждение (например, 3 срабатывания за 2 минуты → алерт).
- Уровни критичности: INFO → WARNING → CRITICAL. Не все WARNING нужно разбудить в 3 утра.
2. Список критичных метрик (must-have)
Разделим на операционные и бизнес-метрики.
Операционные (жизненно важные)
- Температура GPU (°C) — per-GPU и per-rig.
- Частота вентиляторов (%) и RPM.
- Потребление энергии (W) — per-rig и per-PDU.
- Аптайм/статус хоста (online/offline).
- Ошибки хешера (HW errors, rejected shares).
- Температура в комнате/в шкафу (ambient).
- Ошибки питания (undervoltage/overcurrent), события PS_ON.
- Сеть: packet loss > X%, ping до пула > Y ms.
- Температура блока питания (если есть датчик).
Бизнес-метрики (для операторов и владельцев)
- Хешрейт (GH/s или MH/s) — per-rig и aggregated.
- Доходность $/day (по пулу) — усреднённая и моментная.
- % rejected shares — показатель «здоровья» майнера.
- PUE (если доступно) — важный KPI для хостов.
3. Рекомендуемые пороги и логика алертов
Ниже — практичные пороги, которые спасут вам много нервов. Подстройте под свой климат, модели GPU и энергетику.
Температура GPU:
- WARNING: > 70°C (устойчиво 3 минуты).
- CRITICAL: > 85°C (1 минута) → немедленное снижение частоты/уменьшение вентиляторов или shutdown.
Вентиляторы:
- WARNING: RPM ниже 60% от номинала или скорость постоянно растёт > 90% (возьмите в совокупности с temp).
- CRITICAL: вентилятор перестал отвечать / RPM=0 → срочная проверка.
Потребление:
- WARNING: рост потребления >20% от среднего за 15 мин (возможно короткое замыкание).
- CRITICAL: пиковые скачки >40% или сработала защита PDU/Щита.
Сеть:
- WARNING: потеря пакетов 5–10% за 5 минут.
- CRITICAL: packet loss > 30% или ping к пулу > 200 ms → переключение пула/смена провайдера.
Хешрейт и rejected-shares:
- WARNING: падение хешрейта > 10% от baseline за 10 минут.
- CRITICAL: падение > 30% за 5 минут или rejected-shares > 5% за 10 минут.
Аптайм/статус:
- CRITICAL: хост offline (без ответа) — начать скрипты перезапуска и оповещение теха.
4. Настройка в HiveOS — чек-лист
HiveOS даёт много готовых алертов; главная задача — настроить пороги и механизмы доставки.
- Агент на каждом риге: установите последнюю версию.
- Custom scripts: подготовьте скрипты для автоперезапуска майнера, изменения частоты вентиляторов и graceful shutdown.
- Alerts → Email/Telegram/Webhook: подключите Telegram-бота (см. ниже) и webhook в Prometheus / Grafana.
- Group-level templates: сделайте шаблоны алертов для похожих ферм (GPU семейство X = шаблон X).
- Health checks: включите мониторинг PDU и SNMP (если есть).
- Logging: храните лог минимум 30 дней (для RCA).
Пример: правило на падение хешрейта
- условие: hash < baseline*0.85 for 10 min
- действие: notify group + run script: restart miner (3 попытки) → если не помогло, escalate to on-call.
5. Настройка в Awesome Miner — чек-лист
Awesome Miner удобен для гибридов Windows/Linux.
- Подключите все майнеры через API.
- Настройте шаблоны алертов и политики (alert rules).
- Используйте Automation Rules: auto-restart, throttle GPU, notify.
- Integrations: Telegram, Slack, Prometheus (через exporter) и OpsGenie — всё подключаемо.
- Запланируйте Maintenance windows — чтобы обновления не задевали ночные оповещения.
6. Prometheus + Grafana — зачем и как
Prometheus = сбор метрик, Grafana = красивые и полезные дашборды. Роль: централизованный сбор, агрегирование и настойка alertmanager.
Архитектура:
- Exporters (node_exporter / custom exporter от HiveOS/AwesomeMiner) → Prometheus → Alertmanager → Telegram/Webhook/Grafana.
- Хранение метрик: retention 30–90 дней (в зависимости от объёма).
Что экспортировать:
- per-GPU temp, fans, hash, power, uptime, rejected shares.
- PDU metrics: voltage, current per outlet.
- Ambient temp и влажность. Пример правила Prometheus (alerting rule):
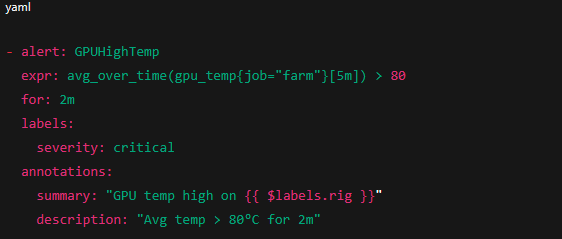
7. Интеграция с Telegram — быстрый старт
Telegram удобен, потому что мессенджер доступен всем.
- Создайте бот через @BotFather → получите токен.
- Создайте групповой чат / канал для алертов. Добавьте бот и получите chat_id.
- В Alertmanager настроить webhook на Telegram API:

4. Формат сообщений: коротко + link to Grafana panel + кнопки (если используете interactive bot). Пример:
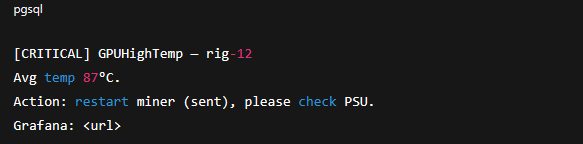
8. Сценарии реагирования — «playbooks»
Каждый алерт должен иметь runbook. Примеры.
A. GPU temp WARNING (>70°C)
- Оповестить on-call (Telegram).
- Автоматический action: увеличить вентиляторы на +10% (скрипт).
- Если temp не упал в 5 минут — send WARNING to operator.
- Если temp >85 → CRITICAL → graceful shutdown rig.
B. Hash drop 15%
- Проверить rejected shares. Если >2% — перезапуск майнера.
- Если перезапуск не помог — изменить пул на backup (auto switch).
- Если после switch hash не восстановился — escalate to engineer.
C. Network packet loss
- Проверить local router (ping gateway).
- Если локально всё ок — переключить rig на backup pool/мобильный канал (если доступен).
- Если исчезло — расследовать isp.
9. Тестирование и отладка алертов
- Стабильно тестируйте «firing» алертов в тестовом канале.
- Делайте учения «simulated incident» раз в квартал — прогоните playbook с оператором.
- Наличие false-positive metrics? Подправьте thresholds или добавьте for: duration.
10. Резервные механизмы и auto-heal
- Auto-restart майнера (3 попытки) + send report.
- Auto-throttle: при повышенной температуры уменьшение частоты на 5–10%.
- Safe-shutdown: если питание пошло в critical state — выключаем риг безопасно.
11. Логирование, RCA и post-mortem
- Храните журналы (logs) минимум 30 дней.
- После инцидента: RCA документ (root cause, timeline, corrective actions) — 1 страница.
- Track KPI: MTTR (mean time to recover), MTTD (mean time to detect), incidents per month.
12. Практические хитрости и «неочевидные» советы
- Baseline: первый месяц соберите данные без алертов; потом выставляйте пороги по среднему+sigma.
- Считайте «собственный прирост шума»: в ночной период хешрейт может падать, но это норм.
- Всегда ставьте mute windows: плановые работы не должны дергать on-call.
- Разделяйте алерты по ответственности: ops vs hardware vs network vs billing.
13. Примеры файлов/скриптов (коротко)
- Скрипт для HiveOS: restart miner via CLI (miner stop/start), change fan speed.
- Webhook handler: small Node.js/Python service to receive alert and call HiveOS API to restart miner.
- Prometheus exporter: lightweight exporter reading HiveOS API and exposing metrics.
14. Внедрение «под ключ» — пошаговый план
- Инвентаризация: соберите список ригов, PDU, IP, baseline метрик — 1 день.
- Развёртывание Prometheus + Grafana + Alertmanager или настройка встроенных алертов HiveOS — 1–2 дня.
- Подключение Telegram bot + тестовый канал — 0.5 дня.
- Шаблоны алертов = по умолчанию (темп/фэн/пауэр/hash/net) — 1 день.
- Скрипты автотерапии (restart, throttle) — 1–2 дня.
- Учение и отладка: симуляция инцидента — 1 день. Итого минимальный MVP: 4–7 рабочих дней.
15. Заключение — что важно помнить
Мониторинг — это не про «поставить графики и забыть». Это цикл: метрика → алерт → действие → ретроспектива. Начните с малого: 6–8 ключевых алертов, проверенные скрипты автотерапии и честные runbooks. Дальше — расширяйте, добавляйте слои (Prometheus, Grafana) и автоматизацию.













